Spring Cloud Stream - using Functional constructs
Preface
Spring Cloud Stream provides a framework to implement messaging in a clean way. The new version 3 brings functional paradigm to the Spring Cloud Stream framework where previously the annotations were used for the same. Docs explain it way better, but I will provide a succint way to get started. Read this after going through the docs. In this blog, I chose Kafka as the message broker.
Getting Started
Add Dependencies
- Cloud Stream
- Kafka
Adding Cloud Stream, lets us create Beans of type Function, Consumer or Supplier. As per the docs - beans of type Supplier, Function or Consumer are treated as defacto message handlers triggering binding of to destinations exposed by the provided binder following certain naming conventions and rules to avoid extra configuration.
Create Beans
In this step, create Producer, Consumer and/or Transformer(which accepts an input and publishes a possibly modified output) beans. I will call these as Functional beans.
Functional beans are tied to input(s) and output(s). The input and output are abstractions and depending on the actual underlying broker it might be a queue or topic or something else.
Supplier acts as a Producer and is tied to only the output. Whatever the Supplier produces is sent to the output.
Consumer, similarly, acts as a consumer of a message. So it is only tied to input. From the input it consumes the message.
Function acts as a transformer and so it consumes a message from the input and produces a new message which is sent to the output.
Binding Names
The input or output is tied to the real world queue names or topic names. To identify each input/output of each function they are associated with a binding name whenever they are referred to in properties or in code.
bindingName for input - <functionName> + -in- + <index>
bindingName for output - <functionName> + -out- + <index>
Index starts from 0. If the function name is uppercase, and it is a Function, then the input binding name is uppercase-in-0 and output binding name is uppercase-out-0.
Publish a message on demand
By default, the Supplier bean is invoked by the Spring Framework periodically every second. Most of the times this is not the behaviour we want.
Usually, a message has to be published in response to another foreign event, say for example, a user registration event.
For these use cases of publishing a message whenever we want, we can make use of StreamBridge. DO NOT create Supplier bean.
Instead declare a property spring.cloud.stream.source with the function name.
- Autowire a bean of
StreamBridge. - Set property:
spring.cloud.stream.source=functionName1;functionName2 - Call
streamBridge.send(...)whenever needed.
Example from the docs:
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, "--spring.cloud.stream.source=toStream");
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("toStream-out-0", body);
}
}
Mandatory Properties
1. Specify function names:
For all functional beans present, specify their names:
spring.cloud.function.definition=functionName1;functionName2
If producer function is not present but publishing is done using StreamBridge, then add: spring.cloud.stream.source=functionName3;functionName4
NOTE: Same functionName should not be present in both the above properties.
These properties act as a hint to the Spring framework to create the bindings required for the messaging.
#EDIT: ALWAYS specify the property spring.cloud.function.definition when Spring Cloud Stream is present in the classpath. This will prevent some unintended surprises. Add this property even if it is not required (for example, you might be using the StreamBridge approach). If there is no value which can be given for this property, then any dummy value like blahblah can be used. For more information see the footnote.
2. Bind Topic Names:
Function Names specified in the above property is bound to the actual topic/queue name using the property:
spring.cloud.stream.bindings.<bindingName>.destination=<topic-name>
Usually Needed Properties
Consumer Group Names (Applicable only to Message Consumers):
Most of the times, there will be multiple instances of the same application running and it is desirable that only on of them gets the message to process. Consumer Groups puts that limitation:
spring.cloud.stream.bindings.<bindingName>.group=<groupName>
Properties to enable Partition Support
Properties have to be set at BOTH Producer and Consumer ends inorder for the partitioning to work properly.
Producer-side configuration
spring.cloud.stream.bindings.<bindingName>.producer.partitionKeyExpression=<expression>
spring.cloud.stream.bindings.<bindingName>.producer.partitionCount=<count>
Example:
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=payload.id
spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
Consumer-side configuration
spring.cloud.stream.bindings.<bindingName>.consumer.partitioned=true
Example: spring.cloud.stream.bindings.func-in-0.consumer.partitioned=true
Note:
If the broker is NOT Kafka or if Kafka’s autoRebalanceEnabled is set to false, then following two additional properties are also needed.
spring.cloud.stream.instanceIndex=<indexOfTheInstance>
spring.cloud.stream.instanceCount=<totalNumberOfInstances>
These properties have to be set properly - instanceIndex shoud be unique for each instance of the microservice. So setting these for autoscaling scenarios will be difficult.
Demo
To play with the demo programs Kafka is required. I have a Docker Compose file which runs both Kafka and a UI called Kafdrop. Run it wih docker-compose up -d and stop it with docker-compose down -v. Once its up, the UI is available at http://localhost:9000
To send messages to Kafka topic:
Log in to the docker container: docker exec -it <containerId> /bin/bash
Run:
bash-4.4# kafka-console-producer.sh --broker-list localhost:9092 --topic funcName-in-0
>{"name":"Sam Spade"}
Running multiple instances of Demo Spring application:
Open multiple terminals and run the following passing different port number each time:
mvn spring-boot:run -Dspring-boot.run.arguments=--server.port=8081
Stream Message Demo without partitioning
Stream Message Demo with partitioning
Without partitioning and consumer groups
When Consumer Group is not enabled, every consumers gets every message.
With partitioning and consumer groups
When both consumer group and partitioning is enabled, each instance is allotted some partitions while other instances are allotted other partitions.
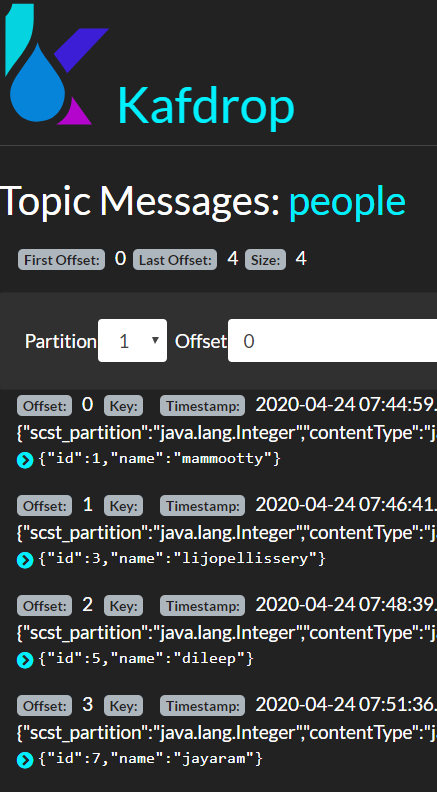
In the demo we have 2 partitions and 4 running instances. Two instances are allotted partitions and other two are idle. Message gets to the partitions according to the id field.
When one of the allotted instance is killed, the partition gets assigned to another one.
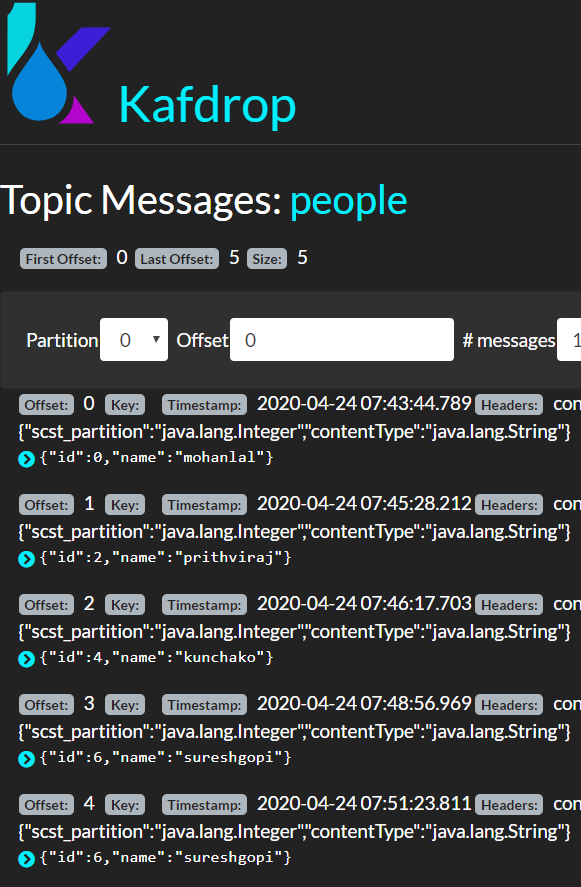
Following images from Kafdrop UI tells the picture at Kafka side where each partition has different data - message gets allotted to the partition on the basis of its id which is specified as the partitionKeyExpression.
Footnotes
I got a weird error in one of my applications when Spring Cloud Stream was used. It was a producer only application which used the StreamBridge to publish a message. So the only property I had was spring.cloud.stream.source.
But when the application started I started getting error message which said something like the following: LoggingHandler: MessagingException: Failed to convert message... No converters present - I don’t have the exact error message now.
The issue which caused this was there was a Spring Boot Actuator bean called JolokiaEndpoint which got autoconfigured. This bean extends Supplier<EndpointServlet> and thus qualifies as a candidate to be picked up by the Spring Cloud Stream.
To prevent above scenario and to avoid any such nasty surprises ALWAYS add the property spring.cloud.function.definition with a non-existing function name. For example:
spring.cloud.function.definition=nonExistingFunctionName
If in the future any function gets added to the application, then nonExistingFunctionName can be replaced with the actual function name.